Testing your code seems like a sane idea, at least from a programmers perspective [eg 1]. As a scientist when it comes to crunching numbers, in the majority of cases, you hack together a small script and hope that it runs as intended. If strange behavior (aka bug) occurs while processing a gigabyte large dataset, you give it a quick fix, pray for the best and start computation all over. After nights of debugging it gets clear that this is not the best approach (or earlier – i have learned it the hard way).
Assuring the correct execution is rather easy for small parts of code. It is obvious what the following (exaggerated simple) function does:
def larger_zero(number):
return number > 0
Problems develop with increasing length of the function or multiple functions/objects interacting with each other. In the real world you are more likely to have a ~1000-lines-of-code data analysis script. It is reading from different files, doing computations and plotting and finally writes the results out. How to assure correct execution in this case?
When your scientific software is modularized (which it ideally is, but this topic is too broad to discuss it here), testing seems pretty straightforward:
- starting at the bottom: test independent functions on their own (the core of unit testing)
- make sure, that the communication between functions works correct
- examine if the whole script does what you intended
Some people argue, that you should write the tests before you start to write your software. In science where you might not know at the beginning what your program should look like at the end, this is not the perfect solution. My current way to go, looks approximately like this (I’m not claiming that there is no room improvements):
- play with the problem, get an idea about the structure of your program
- draft (and maybe write) the tests
- write the actual software, unit test regularly
- if you encounter a bug, write a test reproducing this bug, then debug
- test on a larger scale (for example with a test dataset – if there is one)
- give it a try with the real data (remember: bug -> test to reproduce -> fix the bug)
But enough with the theory, lets look at a simple example. As I am still a novice in the field of (unit) testing, don’t expect too much 😉 Python is the language of my choice for scientific tasks [2]. Aside from unittest (included in the python standard library), pytest [3] seems a good library to get started with unit testing. Installation is straightforward using pip. To illustrate the case I will use a (slightly simplified) piece of code written during my master’s thesis. The quality_mask() function is used to categorize measurements based on quality criteria.
from __future__ import print_function
import numpy as np
def quality_mask(data):
""" """
if data['Zcr'] > -25. and (data['LDRcr'] < - 14 or np.isnan(data['LDRcr'])):
print('# particle influenced')
flag = 1
if data['momentswp'][0][0] < -29.:
#print('# low reflectivity')
flag = 2
if data['momentswp'][0][1] < data['vcr']:
# left of cloud radar and above convective boundary layer
flag = 6
if (len(data['momentswp']) > 1
and data['momentswp'][1][1] > data['vcr']
and data['momentswp'][1][0] > -29.):
flag = 4
if len(data['momentswp']) > 6 \
and data['momentswp'][4][0] > -30.:
# print('# too many peaks (melting layer)')
flag = 5
#if snr_main_peak < 20.:
if data['SNRwp'] < 15.:
# print('# low snr')
flag = 3
elif data['LDRcr'] > - 14. and data['Zcr'] > 0.:
# melting layer
flag = 5
else:
# not particle influence
flag = 0
return flag
As there are several input parameters and a lot if-conditions you want to get sure, that classification works as expected. This calls for a unit test. It can be located in a separate file, to keep things clean. Each test has its own data dictionary and checks for the correct output.
from __future__ import print_function
import numpy as np
def quality_mask(data):
""" """
if data['Zcr'] > -25. and (data['LDRcr'] < - 14 or np.isnan(data['LDRcr'])):
print('# particle influenced')
flag = 1
if data['momentswp'][0][0] < -29.:
#print('# low reflectivity')
flag = 2
if data['momentswp'][0][1] < data['vcr']:
# left of cloud radar and above convective boundary layer
flag = 6
if (len(data['momentswp']) > 1
and data['momentswp'][1][1] > data['vcr']
and data['momentswp'][1][0] > -29.):
flag = 4
if len(data['momentswp']) > 6 \
and data['momentswp'][4][0] > -30.:
# print('# too many peaks (melting layer)')
flag = 5
#if snr_main_peak < 20.:
if data['SNRwp'] < 15.:
# print('# low snr')
flag = 3
elif data['LDRcr'] > - 14. and data['Zcr'] > 0.:
# melting layer
flag = 5
else:
# not particle influence
flag = 0
return flag
Now we are ready to run the test with py.test -v test_calculate.py. The output looks like this:
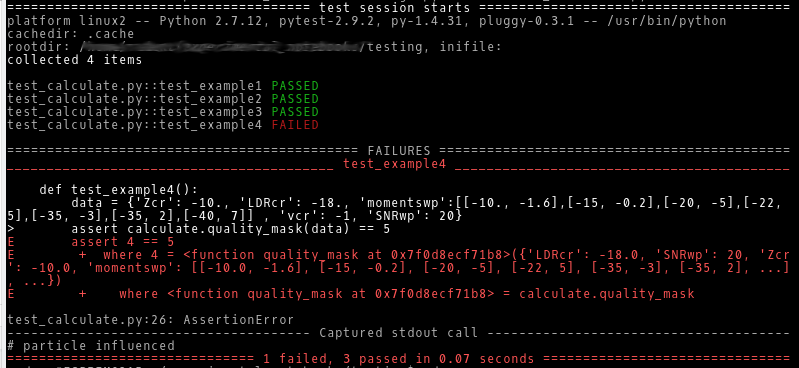 The first three test passed nicely. The forth one fails, either caused by a bug in the function or – in this case – an error in the data used for that test.
The first three test passed nicely. The forth one fails, either caused by a bug in the function or – in this case – an error in the data used for that test.
Furthermore the test procedure is very fast: 0.07s. You can use it frequently during and after coding, to ensure code quality without loosing too much time. Many professional teams run their tests every time they commit to their repository or even automated during the night.
Further reading
- [1] http://www.bbc.co.uk/academy/technology/article/art20150223103348419
- [2] Langtangen, A Primer on Scientific Programming with Python link
- [3] http://docs.pytest.org/en/latest/
- TDD for Scientists